Hadoop Nedir?

Hadoop Nedir?
RDBMS(Relational Database Management System) yani ilişkisel veri tabanı yönetim sistemlerinden farklı olarak verileri tek bir bilgisayarda tutmayıp gelen verileri -her birinin kendine ait işlemcisi ve rami- olan Node’lerde(küme) HDFS dosya sistemi ile denormalize bir şekilde veriyi saklayan ve işlenmesine olanak sağlayan açık kaynak kodlu kütüphanedir.
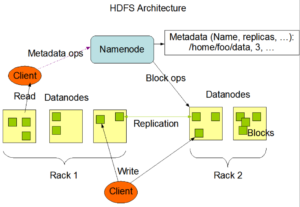
HDFS(Hadoop Distributed File System) nedir?
Sıradan sunucuların disklerini bir araya getirerek büyük ve sanal bir disk oluşturan dosya sistemidir. Bu sayede çok büyük boyuttaki dosyaları sistemde saklayabilir ve işlenmesine olanak sağlar. Bu dosyalar bloklar halinde (varsayılan 64MB) birden fazla ve farklı sunucu
üzerine (varsayılan 3 kopya) dağıtılarak yedeklenir. Bu sayede veri kaybı önlenmiş olur. Ayrıca HDFS çok büyük boyutlu dosyalar üzerinde okuma işlemi imkanı sağlar, ancak rastlantısal erişim (random access) özelliği bulunmaz. HDFS, NameNode ve DataNode süreçlerinden (process) oluşmaktadır.
NameNode ana (master) süreç olarak blokların sunucular üzerindeki dağılımından, yaratılmasından, silinmesinden, bir blokta sorun meydana geldiğinde yeniden oluşturulmasından ve her türlü dosya erişiminden sorumludur. Kısacası HDFS üzerindeki tüm dosyalar hakkındaki bilgiler (metadata) NameNode tarafından saklanır ve yönetilir.
DataNode ise işlevi blokları saklamak olan işçi (slave) süreçtir. Her DataNode kendi yerel diskindeki veriden sorumludur. Ayrıca diğer DataNode’lardaki verilerin yedeklerini de barındırır. DataNode’lar küme içerisinde birden fazla olabilir.
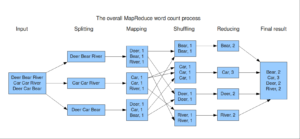
Hadoop’un dağıtık veri işleme modeli: Map-Reduce
Tüm verileri merkeze toplamadığımız için bütün işlemler ayrı ayrı Node’lerde yapılır. Bu işlemler bittikten sonra her Node’den dönen cevap alınır ve toplam sonuç oluşturulur. Bu işlemler bütüne Map-Reduce denir.
Map-Reduce Nasıl Çalışır?
Yazılışı çeşitli dökümanlarda birleşik gibi görünsede Map-Reduce aslında Map (Mapping) ve Reduce (Reducing) iki ayrı işlem yapan, bir arada çalışarak dağıtık dosya sistemlerinde veri analizinin oldukça kolaylaştırılmasını sağlayan methodlardır. Map, bir listedeki her bir elemana tek tek bir kuralı uygular. Reduce, Map ile elde edilen sonuçları belli bir sistematik ile analiz ederek birleştirir. Yaptığı analiz sonunda da bir değer döndürür.
- Input: Veri girişlerinin yapıldığı adımdır.
- Splitting: Gelen veriler bu aşamada işlemesi daha kolay olabilmesi için parçalara bölünür.
- Mapping: Veriler bu aşamada ilgili düğümlere de dağıtılır ve kaç tane yedeği olacağı bu adımda belirtilir. Ve daha sonrasında her ilgili düğümde işlenir.
- Shuffling: Her düğümde verilerin sayma işlemi yapılır. Örneğin bir text dokümanını input olarak verdiysek ve sonuç olarak hangi kelimenin kaç defa geçtiğini arıyorsak bu aşamada kelime sayıları Node’lerde belirlenir.
- Reducing: Her Node’den gelen sonuç bu aşamada toplanır.
- Final Result: Sonuçlar artık elimizdedir. Bunun raporlamasını yapabiliriz.