Azure üzerinde Data Pipeline Oluşturma

Merhabalar bu yazımda sizlere Bulut Servis Sağlayıcılarından olan Azure üzerinde bir Data Pipeline oluşturma sürecini anlatacağım. Gelin isterseniz ilk önce projemizin mimarisine bakalım.
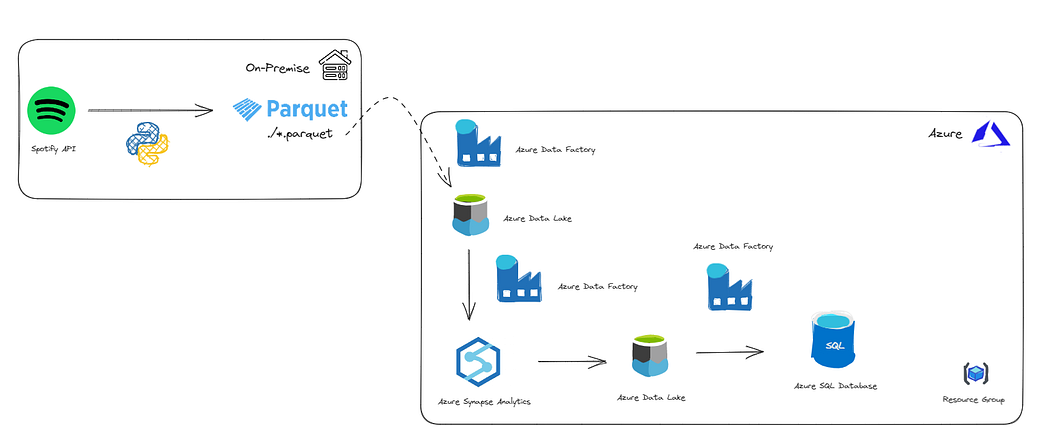
Mimarimiz yukarıda görmüş olduğunuz gibidir. Veri akışı anlatımına geçmeden önce Azure üzerinde kullandığımız servisleri kısaca bir tanıyalım.
Azure Resource Group → Microsoft Azure bulut platformunda kaynaklarınızı yönetmek için kullanılan bir yapıdır. Azure’da oluşturduğunuz kaynakları, sanal makineleri, depolama hesaplarını, ağ yapılandırmalarını, uygulamaları ve diğer hizmetleri mantıksal bir grup içinde toplamanızı sağlar.
Azure Data Factory → Microsoft Azure bulut platformunda veri entegrasyonu ve veri işleme işlerini otomatikleştirmek için kullanılan bir hizmettir. Azure Data Factory, farklı veri kaynakları arasında veri hareketini, dönüşümünü ve işlenmesini sağlayarak veri entegrasyonunu kolaylaştırır.
Azure Synapse Analytics → Microsoft Azure bulut platformunda, verilerinizi analiz etmek, işlemek ve raporlamak için kullanabileceğiniz güçlü bir veri analitiği çözümüdür.Azure Synapse Analytics, veri ambarı, veri entegrasyonu, veri sorgulama ve büyük veri analitiği gibi işlemleri tek bir platformda birleştirir.
Azure Data Lake → Büyük veri depolama ve analizi için kullanılan bir hizmettir. Azure bulut platformunda, yapılandırılmış ve yapılandırılmamış büyük veri kütlelerini güvenli ve ölçeklenebilir bir şekilde depolamak için kullanılır.
Azure SQL Database → Microsoft Azure bulut platformunda barındırılan ilişkisel veritabanı hizmetidir. Geleneksel SQL Server veritabanının bulut tabanlı bir sürümü olarak düşünülebilir.
Mimariye baktığımızda ilk kısımda On-Premise tarafta gerçekleşen işlemlerimiz mevcut. Gelin isterseniz ilk olarak lokalimizde çalışan python koduna ve çıktısına bir bakalım.
import spotipy
from spotipy.oauth2 import SpotifyClientCredentials
import pandas as pd
from datetime import date
import configparserparser = configparser.ConfigParser()
parser.read(“conf.ini”)client_credentials_manager = SpotifyClientCredentials(
client_id = parser.get(“credentials”,“CLIENT_ID”),
client_secret = parser.get(“credentials”, “CLIENT_SECRET”)
)sp = spotipy.Spotify(client_credentials_manager = client_credentials_manager)
playlist_link = ‘https://open.spotify.com/playlist/37i9dQZF1EIWxkuBxGv3mp’
playlist_URI = playlist_link.split(“/”)[-1]
data = sp.playlist_tracks(playlist_URI)
date_str = str(date.today())album_list = []
for row in data[“items”]:
album_id = row[“track”][“album”][“id”]
album_name = row[“track”][“album”][“name”]
album_release_date = row[“track”][“album”][“release_date”]
album_total_tracks = row[“track”][“album”][“total_tracks”]
album_url = row[“track”][“album”][“external_urls”][“spotify”]
album_element = {
“album_id”: album_id,
“name”: album_name,
“album_release_date”: album_release_date,
“album_total_tracks”: album_total_tracks,
“album_url”: album_url
}
album_list.append(album_element)artist_list = []
for row in data[“items”]:
for key, value in row.items():
if key == “track”:
for artist in value[“artists”]:
artist_dict = {
“artist_id”: artist[“id”],
“artist_name”: artist[“name”],
“external_url”: artist[“href”]
}
artist_list.append(artist_dict)song_list = []
for row in data[“items”]:
song_id = row[“track”][“id”]
song_name = row[“track”][“name”]
song_duration = row[“track”][“duration_ms”]
song_url = row[“track”][“external_urls”][“spotify”]
song_popularity = row[“track”][“popularity”]
song_added = row[“added_at”]
album_id = row[“track”][“album”][“id”]
artist_id = row[“track”][“album”][“artists”][0][“id”]
song_element = {
“song_id”: song_id,
“song_name”: song_name,
“duration_ms”: song_duration,
“url”: song_url,
“popularity”: song_popularity,
“song_added”: song_added,
“album_id”: album_id,
“artist_id”: artist_id
}
song_list.append(song_element)album_df = pd.DataFrame.from_dict(album_list)
album_df = album_df.drop_duplicates(subset = [“album_id”])artist_df = pd.DataFrame.from_dict(artist_list)
artist_df = artist_df.drop_duplicates(subset = [“artist_id”])song_df = pd.DataFrame.from_dict(song_list)
album_df[“release_date”] = pd.to_datetime(album_df[“album_release_date”])
song_df[“song_added”] = pd.to_datetime(song_df[“song_added”])song_df.to_parquet(f”data\\{date_str}_song_ds.parquet”,engine=“fastparquet”)
album_df.to_parquet(f”data\\{date_str}_album_ds.parquet”,engine=“fastparquet”)
artist_df.to_parquet(f”data\\{date_str}_artist_ds.parquet”,engine=“fastparquet”)
Conf.ini
[credentials]
CLIENT_ID = XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
CLIENT_SECRET = XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
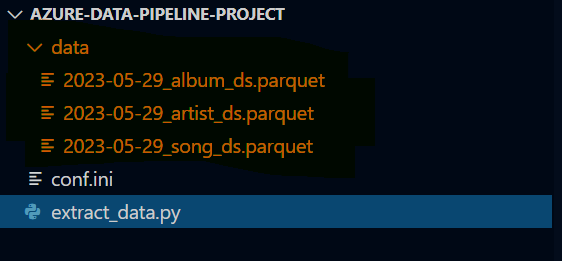
Görmüş olduğunuz Python kodu Spotify API’na istekte bulunarak dönen sonuçtan 3 farklı veri seti elde ederek bunları parquet formatında belirtilen dizine kaydediyor.
Evet lokalimizdeki işlemleri böylelikle bitiyoruz. Şimdi Azure üzerindeki servislerimizi oluşturarak işlemlerimize devam edelim.
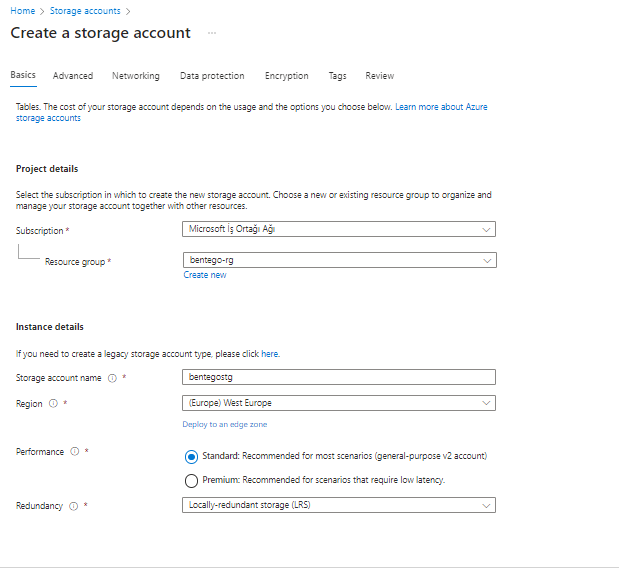
Resource Group Oluşturma İşlemi:

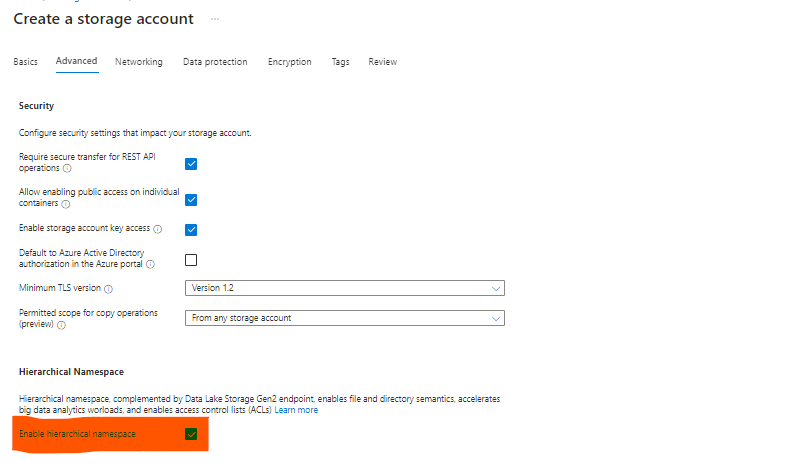
Azure Data Lake Oluşturma İşlemi:
Azure Data Factory Oluşturma İşlemi:
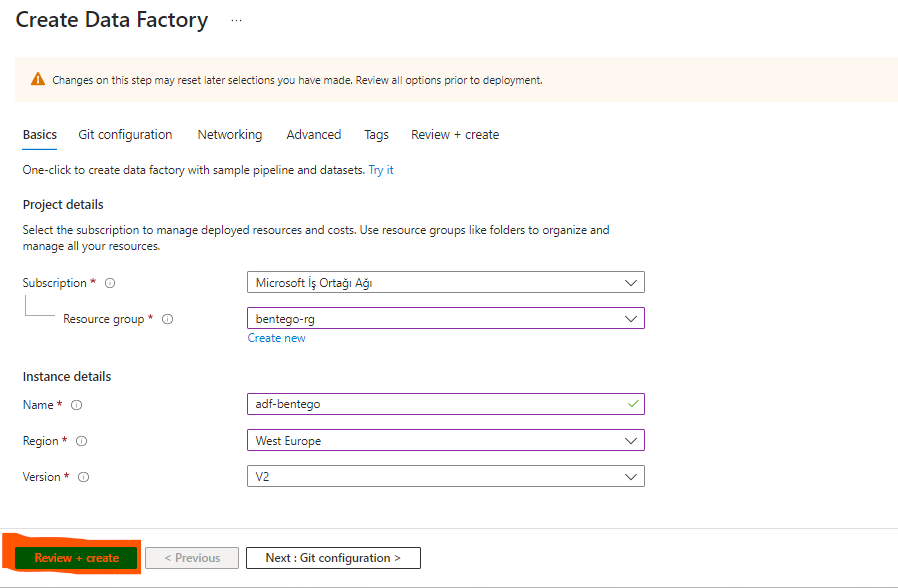
Azure Synapse Analytics Oluşturma İşlemi:


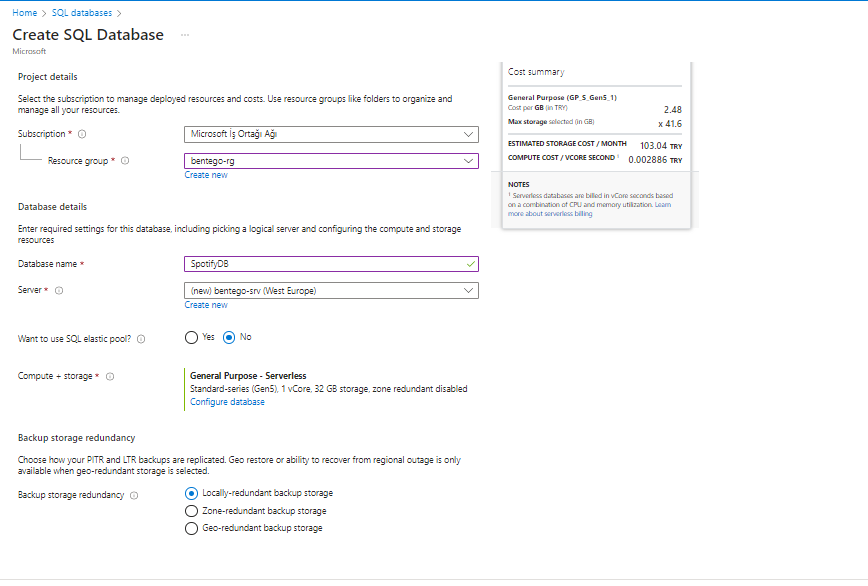
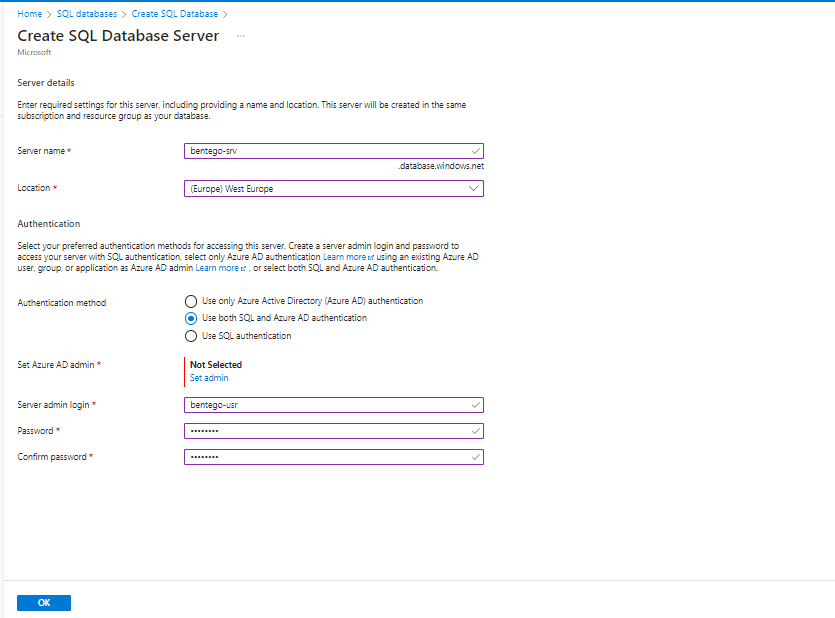
Azure SQL Database Oluşturma İşlemi:
Gerekli servisleri oluşturduğumuza göre Azure Data Factory Studio ekranına giderek Manage sekmesinden Integration Runtimes(IR) kısmına gelerek lokalimizle bağlantı sağlayacak yeni bir tanesini oluşturacağız.
Self-Hosted IR Oluşturma İşlemi:
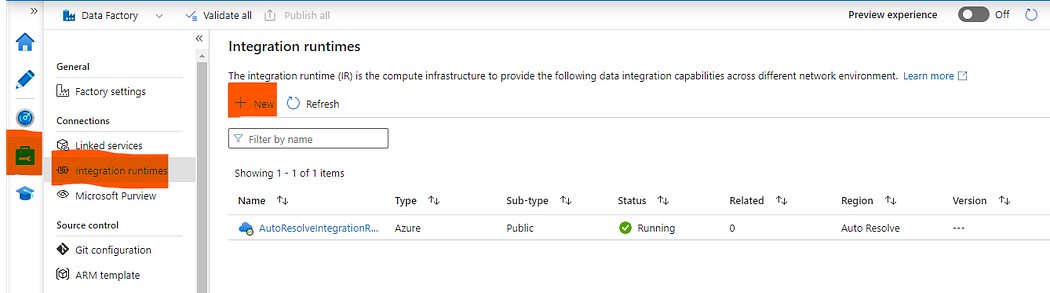
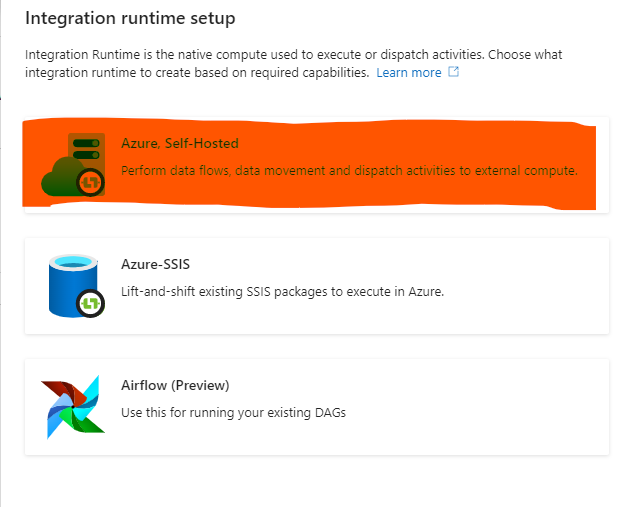
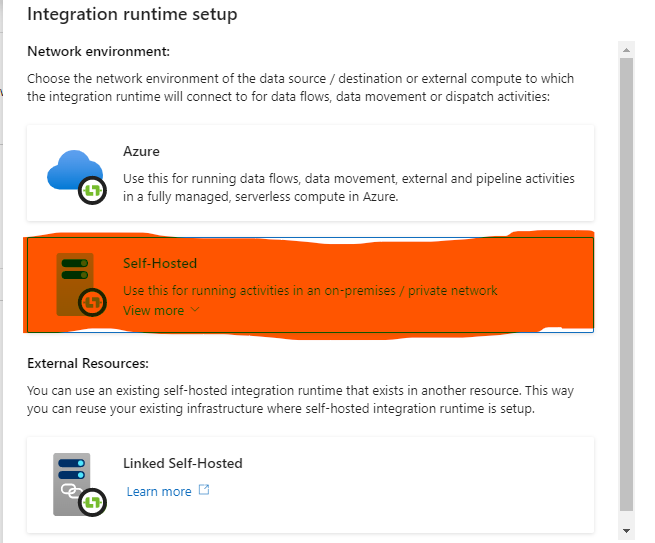

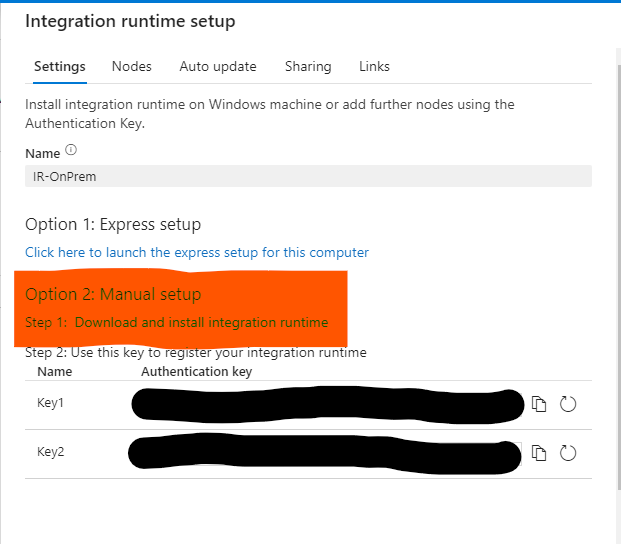
Option 2‘deki link’e tıklayarak indirme işlemini gerçekleştiriyoruz. İşlem bittikten sonra çıkacak ekrana Key1‘i kopyalayarak ilgili alana yapıştırıyoruz.



Başarılı bir şekilde lokalimiz ile bağlantı sağlayacak ve ilgili işlemleri orada gerçekleştirecek olan IR’ı oluşturmuş olduk.
Data Factory üzerinde oluşturacağımız Pipeline da lokalimizde ki parquet dosyalarını kullanabilmek için Linked Service oluşturacağız onu da aşağıdaki adımları takip ederek oluşturabilirsiniz.

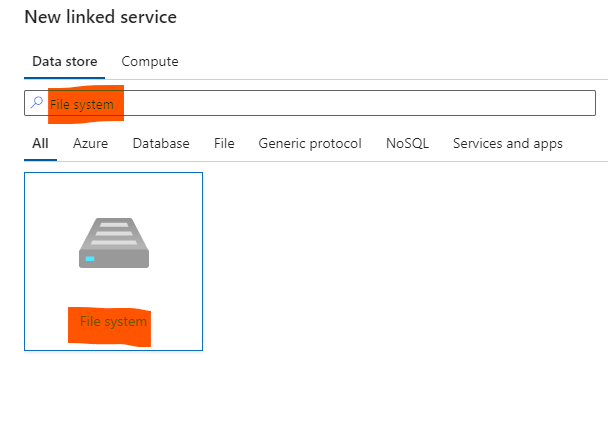
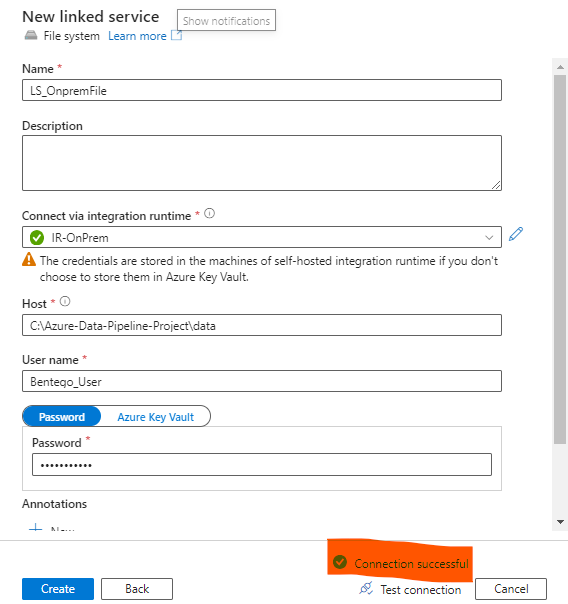
Oluşturacağımız Data Pipeline içerisinde bu LS(Linked Service)’i kullanarak lokal’deki her bir parquet formatı eğer bugünün tarihi ile başlıyorsa onu alarak Azure Data Lake’deki belirttiğimiz dizine kopyalayacak.
DP_Extract_OnpremToADL2:

Yukarıda görmüş olduğunuz Data Pipeline’ı açıklamak gerekirse yaptığı iş Get Metadata’yı kullanarak lokal’deki her parquet dosyasının dosya ismini ForEach Loop’unda döndürek eğer bugünün tarihiyle başlıyorsa kopyalama işlemini gerçekleştirecek eğer değilse hiçbir işlem yapmayacak.Bu kontrolü yapan Activity ‘If Condition’ ve koşulu yapan kod ise aşağıdaki gibidir.
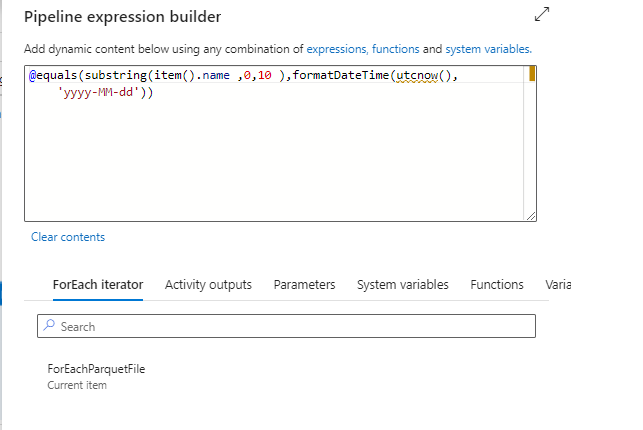
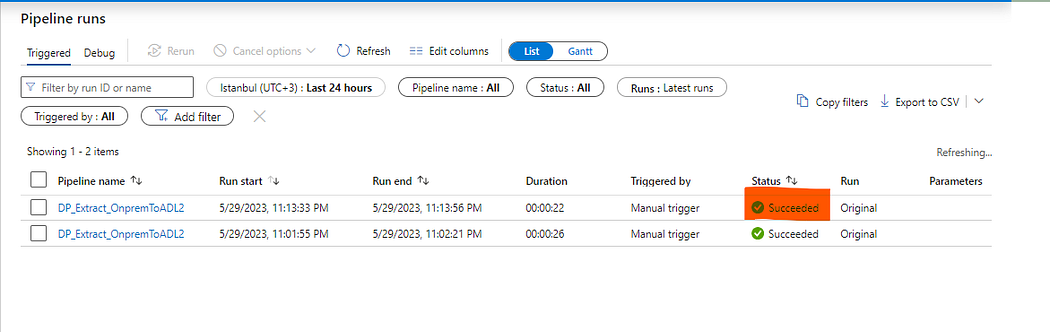
Data Pipeline’ı çalıştırdığımızda başarılı bir şekilde çalıştığını görmekteyiz. Azure Data Lake üzerindeki belirttiğimiz dizini kontrol ederek veriler başarılı şekilde gelmiş mi şimdi ona bakalım.
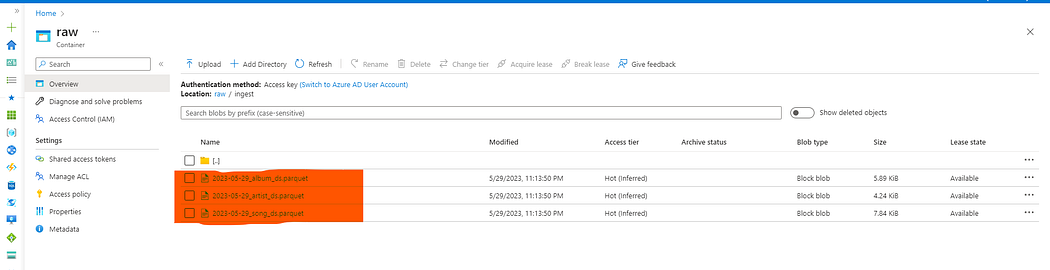
Lokalimizdeki veri setlerinin başarılı şekilde kopyalandığı görmekteyiz.
Bir sonraki aşamamız Azure Synapse Analytics üzerinde Spark Pool oluşturarak veri temizleme ve dönüştürme işlemi uygulayacağız.
Spark Pool Oluşturma İşlemi:

from notebookutils import mssparkutils
from pyspark.sql.functions import *
from pyspark.sql.types import *accountname=“bentegostg”
sourcecontainer=“raw”
LinkedService=“bentego-synapse-ws-WorkspaceDefaultStorage”
sourceFile_location=“ingest”
destinationcontainer=“refined”spark.conf.set(“spark.storage.synapse.linkedServiceName”,LinkedService)
spark.conf.set(“fs.azure.account.oauth.provider.typ”,“com.microsoft.azure.synapse.tokenlibrary.LinkedServiceBasedTokenProvider”)
spark.conf.set(“spark.sql.parquet.writeLegacyFormat”,“true”)SongCustomSchema = StructType([
StructField(“song_id”, StringType(), True),
StructField(“song_name”, StringType(), True),
StructField(“duration_ms”, LongType(), True),
StructField(“url”, StringType(), True),
StructField(“popularity”, LongType(), True),
StructField(“song_added”, StringType(), True),
StructField(“album_id”, StringType(), True),
StructField(“artist_id”, StringType(), True)
]
)song_df = spark \
.read \
.schema(SongCustomSchema) \
.parquet(f”abfss://{sourcecontainer}@{accountname}.dfs.core.windows.net/{sourceFile_location}/2023-05-29_song_ds.parquet”)song_df = song_df \
.withColumn(“duration_ms”,col(“duration_ms”).cast(IntegerType())) \
.withColumn(“popularity”,col(“popularity”).cast(IntegerType())) \
.drop(col(“song_added”))AlbumCustomSchema = StructType([
StructField(“album_id”, StringType(), True),
StructField(“name”, StringType(), True),
StructField(“album_release_date”, StringType(), True),
StructField(“album_total_tracks”, LongType(), True),
StructField(“album_url”, StringType(), True),
StructField(“release_date”, StringType(), True)
]
)album_df = spark \
.read \
.schema(AlbumCustomSchema) \
.parquet(f”abfss://{sourcecontainer}@{accountname}.dfs.core.windows.net/{sourceFile_location}/2023-05-29_album_ds.parquet”)album_df = album_df \
.withColumn(“album_total_tracks”,col(“album_total_tracks”).cast(IntegerType())) \
.withColumn(“album_release_date”,to_date(col(“album_release_date”),“yyyy-MM-dd”)) \
.drop(“release_date”)ArtistCustomSchema = StructType([
StructField(“artist_id”, StringType(), True),
StructField(“artist_name”, StringType(), True),
StructField(“external_url”, StringType(), True),
]
)artist_df = spark \
.read \
.schema(ArtistCustomSchema) \
.parquet(f”abfss://{sourcecontainer}@{accountname}.dfs.core.windows.net/{sourceFile_location}/2023-05-29_artist_ds.parquet”)album_df.write \
.mode(“overwrite”) \
.format(“parquet”) \
.option(“header”,“true”) \
.option(“inferSchema”,“true”) \
.save(f”abfss://{destinationcontainer}@{accountname}.dfs.core.windows.net/album/”)artist_df.write \
.mode(“overwrite”) \
.format(“parquet”) \
.option(“header”,“true”) \
.option(“inferSchema”,“true”) \
.save(f”abfss://{destinationcontainer}@{accountname}.dfs.core.windows.net/artist/”)
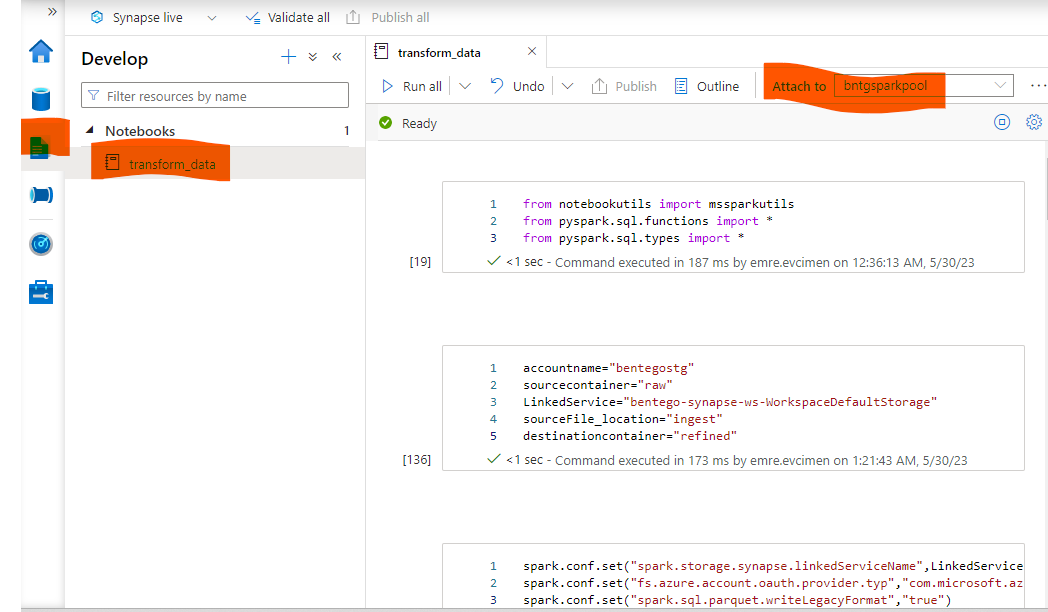
Spark Pool’u oluşturduktan sonra Developer sekmesinden Notebook oluşturarak yukarıdaki görmüş olduğunuz kodları yazıyoruz. Normal PySpark kodlarımızı yazarak verinin düzgün ve temizlenmiş halini yine Azure Data Lake üzerindeki belirtiğimiz dizinlere yolluyoruz.


Kontrol ettiğimizde verilerin başarılı şekilde dizinlere yazıldığını görmekteyiz.
Yukarıda oluşturduğumuz Notebook’u Data Factory üzerinde oluşturduğumuz Data Pipeline içerisinden çağırmak için Azure Data Factory’i servisine Synapse Administrator yetkisi vermemiz gerekli.

Şimdi Azure Data Factory kısmına gidirek Synapse kısmında oluşturduğumuz Notebook’u bağlanabilmesi için yeni bir Linked Service oluşturalım.
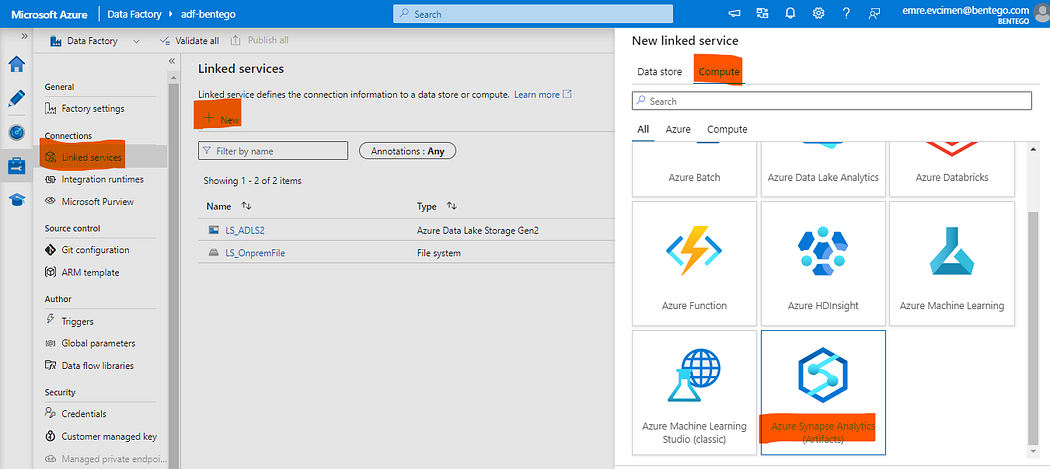
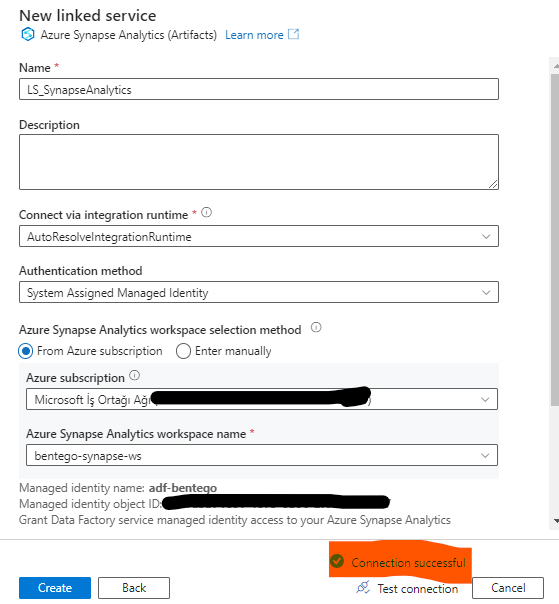
Başarılı şekilde bağlantımızı oluşturduk. Data Pipeline oluştururak Notebook’u birde oradan çağıralım.
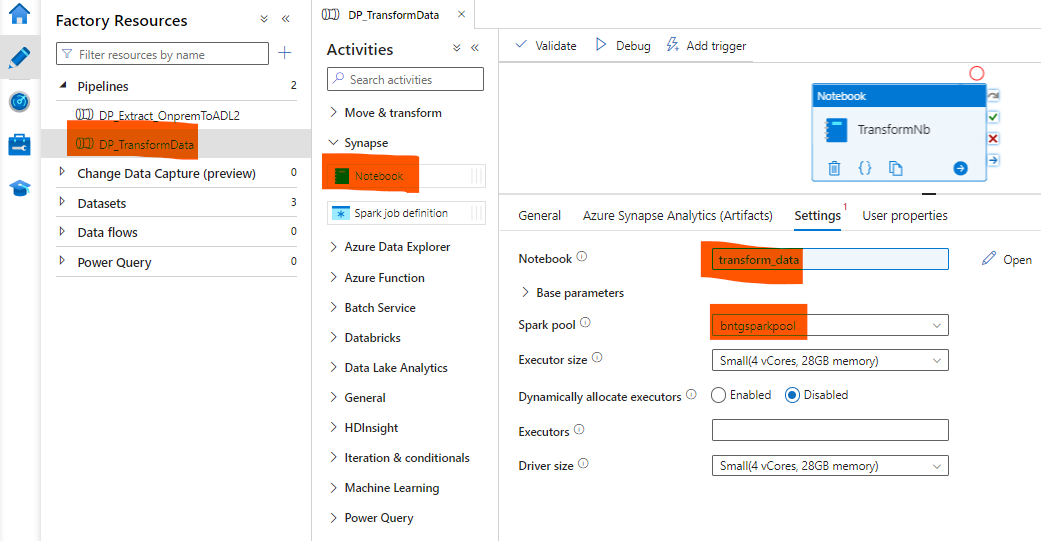
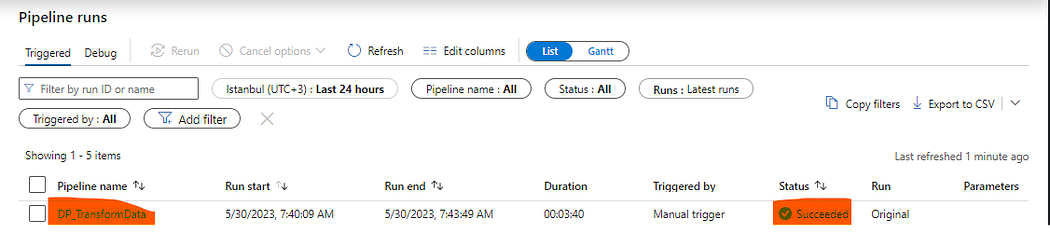
Data Pipeline’ı çalıştırdığımızda başarılı bir şekilde çalıştığını görmekteyiz.
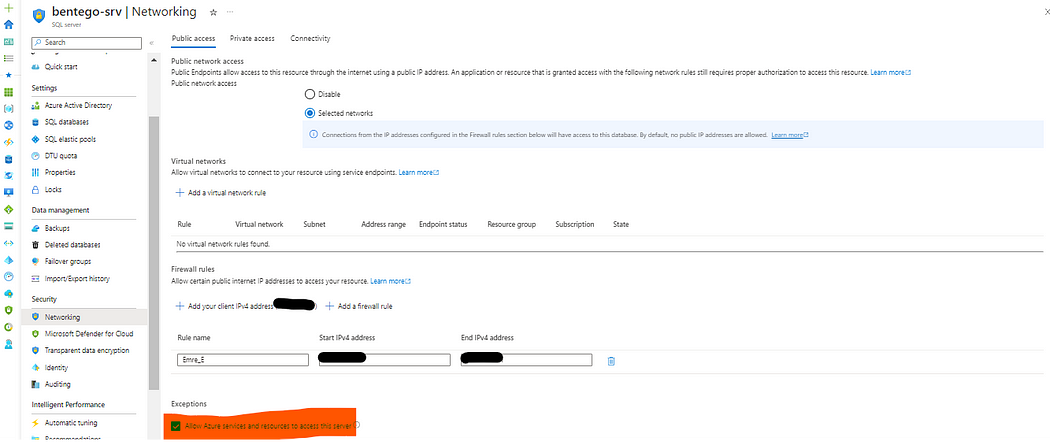
Çalışan Pyspark Job’ımız temizlenmiş ve dönüştürülmüş veriyi başka bir dizine kaydetmiş oldu. Bu veri setlerini şimdi de Azure SQL Database kısmında oluşturduğumuz SpotifyDB’sinin altında tablolar oluşturarak oraya aktaracağız. Data Factory servisinin Azure SQL Database servisine erişebilmesi için aşağıdaki ayarı yapmalısınız.
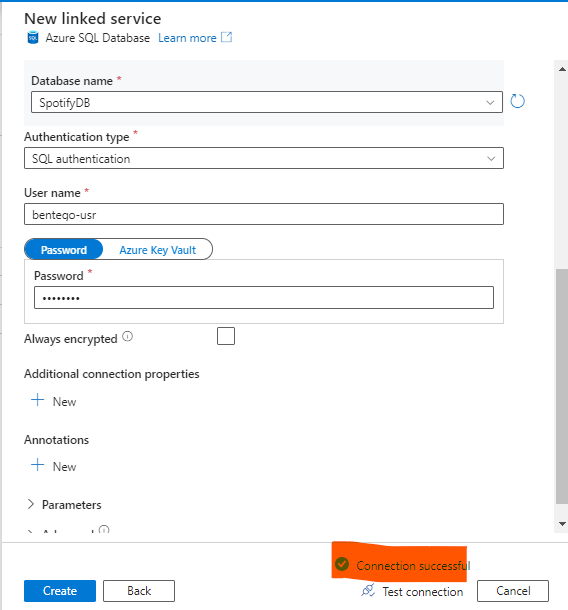

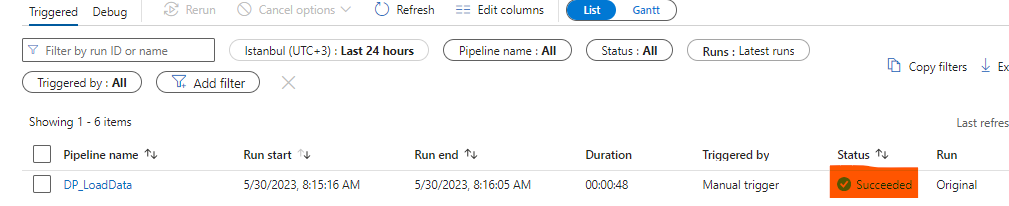

Umarım sizler için faydalı bir yazı olmuştur. Herhangi bir sorunuz veya öneriniz var ise benimle iletişime geçebilirsiniz. Teşekkürler, görüşmek üzere 👋