Kafka Connect ile HDFS’e Veri Gönderme İşlemi

Kafka Connect ile HDFS’e Veri Gönderme İşlemi
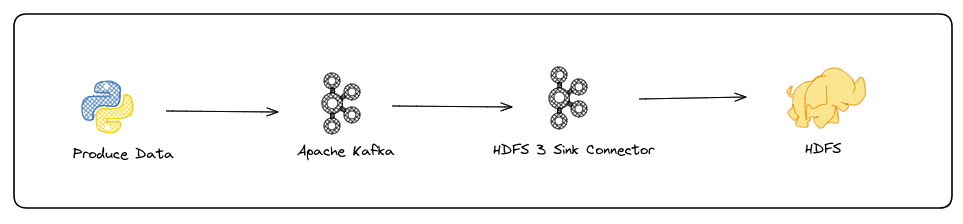
Merhabalar bu yazımda sizlere Kafka’da bulunan verilerimizi nasıl Kafka Connector yardımı ile HDFS’e taşıyabileceğimizi göstereceğim. İlk önce gerekli Connector’umuzu indirelim ve servislerimizi başlatalım.
# HDFS3 Sink Connector indirme işlemi
confluent-hub install confluentinc/kafka-connect-hdfs3:1.1.25# Gerekli servisleri başlatma
confluent local services zookeeper start
confluent local services kafka start
confluent local services schema-registry start
confluent local services connect start# Servislerin durumunu takip etmek için
confluent local services status# Control Center yerine kullanacağım AKHQ servisini başlatmak için
java -Dmicronaut.config.files=akhq.yml -jar akhq.jar
# akhq.yml içeriği
akhq:
connections:
local:
properties:
bootstrap.servers: “localhost:9092”
schema-registry:
url: “http://localhost:8881”
connect:
– name: “connect”
url: “http://localhost:8083”
micronaut:
server:
port: 8880AKHQ Web UI erişimi için: http://localhost:8880/ui/
Gerekli servislerimizi başlattık ve çalışma durumlarını kontrol ettikten sonra şimdi ise Kafka’da berlittiğimiz topic’e veri aktaracak olan Python kodumuza bakalım.
import pandas as pd
from faker import Faker
import random as rd
import time
from confluent_kafka import avro
from confluent_kafka.admin import AdminClient, NewTopic
from confluent_kafka.avro import AvroProducer,CachedSchemaRegistryClient
import re
import datetime
SCHEMA_REGISTRY_URL = "http://localhost:8881"
BROKER_URL = "localhost:9092"
admin_client = AdminClient({'bootstrap.servers': BROKER_URL})
order_topic = [NewTopic('order-topic', num_partitions=1, replication_factor=1)]
fs = admin_client.create_topics(order_topic)
schema = avro.loads(
"""{
"type":"record",
"name":"myrecord",
"fields": [
{
"name": "CustomerID",
"type": "int"
},
{
"name": "CustomerName",
"type": "string"
},
{
"name": "Email",
"type": "string"
},
{
"name": "Address",
"type": "string"
},
{
"name": "State",
"type": "string"
},
{
"name": "PhoneNumber",
"type": "string"
},
{
"name": "InvoiceDate",
"type": "string"
},
{
"name": "StockCode",
"type": "string"
},
{
"name": "Description",
"type": "string"
},
{
"name": "UnitPrice",
"type": "float"
},
{
"name": "Quantity",
"type": "int"
}
]
}"""
)
schema_registry = CachedSchemaRegistryClient({"url": SCHEMA_REGISTRY_URL})
data = pd.read_csv('OnlineRetail.csv', sep = ';')
data["InvoiceNo"] = data["InvoiceNo"].str.replace('A','')
data["InvoiceNo"] = data["InvoiceNo"].str.replace('C','')
data["InvoiceNo"] = data["InvoiceNo"].astype("int64")
data["StockCode"] = data["StockCode"].astype("string")
data["Description"] = data["Description"].astype("string")
data["UnitPrice"] = data["UnitPrice"].str.replace(',','.').astype("float")
cols = ['StockCode','Description', 'UnitPrice']
Stock_Desc_Unit_lst = data[cols].values.tolist()
fake = Faker()
def create_data(x):
project_data = {}
for i in range(x):
project_data[i] = {}
project_data[i]['CustomerID'] = i + 1
project_data[i]['Name'] = fake.name()
return project_data
df = pd.DataFrame(create_data(5000)).transpose()
cols = ['CustomerID','Name']
CustomerID_Name = df[cols].values.tolist()
Q_df = data[data["Quantity"]>0]
Quantity = Q_df["Quantity"].values.tolist()
now = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
def produce_kafka_dict(topic_name,json_as_dict):
producer=AvroProducer({"bootstrap.servers": BROKER_URL}, schema_registry=schema_registry)
producer.produce( topic=topic_name,
value=json_as_dict,
value_schema=schema)
producer.flush()
while True:
order={}
n = rd.randint(1,10)
time.sleep(rd.randint(1,15))
CID_Name = rd.choice(CustomerID_Name)
order["CustomerID"]= CID_Name[0]
order["CustomerName"] = CID_Name[1]
order["Email"] = CID_Name[1].lower().replace(' ','.') + "@gmail.com"
order["Address"] = fake.address().replace('\n',' ')
order["State"] = re.findall("[A-Z]{2}", order["Address"])[0]
order["PhoneNumber"] = fake.phone_number()[0:10]
order["InvoiceDate"] = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
for a in range(n):
Stock_Desc_Unit = rd.choice(Stock_Desc_Unit_lst)
order["StockCode"] = Stock_Desc_Unit[0]
order["Description"] = Stock_Desc_Unit[1]
order["UnitPrice"] = Stock_Desc_Unit[2]
order["Quantity"] = rd.choice(Quantity)
produce_kafka_dict('order-topic',order)
print(order)
Yukarıdaki kod’u özetlemek gerekirse yapacağı iş random bir şekilde sipariş verisi yaratarak bunu avro formatında Kafka’da istediğimiz topic’e iletmek. Örnek çıktı aşağıdaki gibidir:
{‘CustomerID’: 824, ‘CustomerName’: ‘Robert Bullock’, ‘Email’: ‘robert.bullock@gmail.com’, ‘Address’: ‘9618 Chambers Centers Apt. 343 Kevinmouth, WA 39994’, ‘State’: ‘WA’, ‘PhoneNumber’: ‘399.352.69’, ‘InvoiceDate’: ‘2023-06-04 21:44:54’, ‘StockCode’: ‘23371’, ‘Description’: ‘SET 36 COLOUR PENCILS SPACEBOY’, ‘UnitPrice’: 2.46, ‘Quantity’: 1}
Kafka’ya iletilen verileri Kafka CLI yardımı ile de görüntülemek istersek aşağıdaki script’i kullanabiliriz.
kafka-avro-console-consumer \
–bootstrap-server localhost:9092 \
–topic order-topic \
–property schema.registry.url=http://localhost:8881
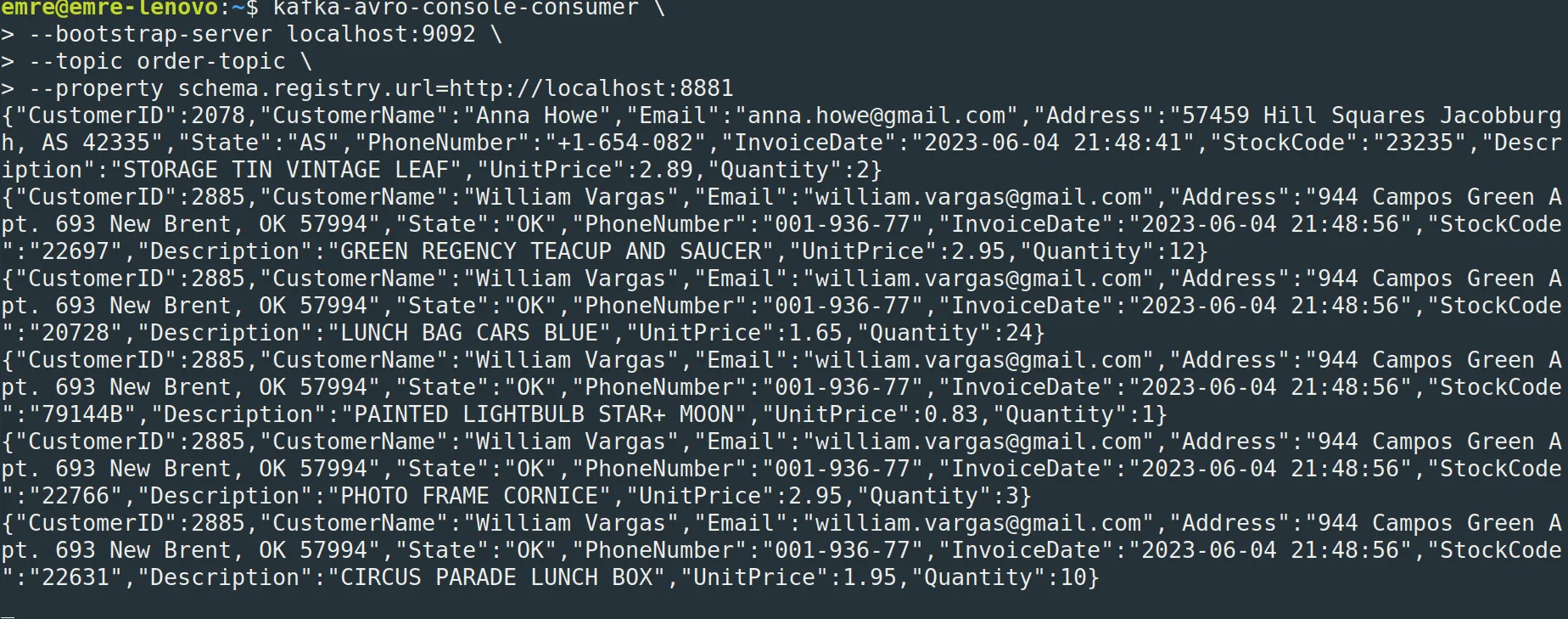
Python kodunu durdurmadığınız sürece sürekli sipariş verisi üretilip istediğimiz topic’e iletilecek. Şimdi gelin bu verileri parquet formatında HDFS’e yazmamızı sağlıyacak connector konfigürasyonunu oluşturup bunu çalıştıralım.
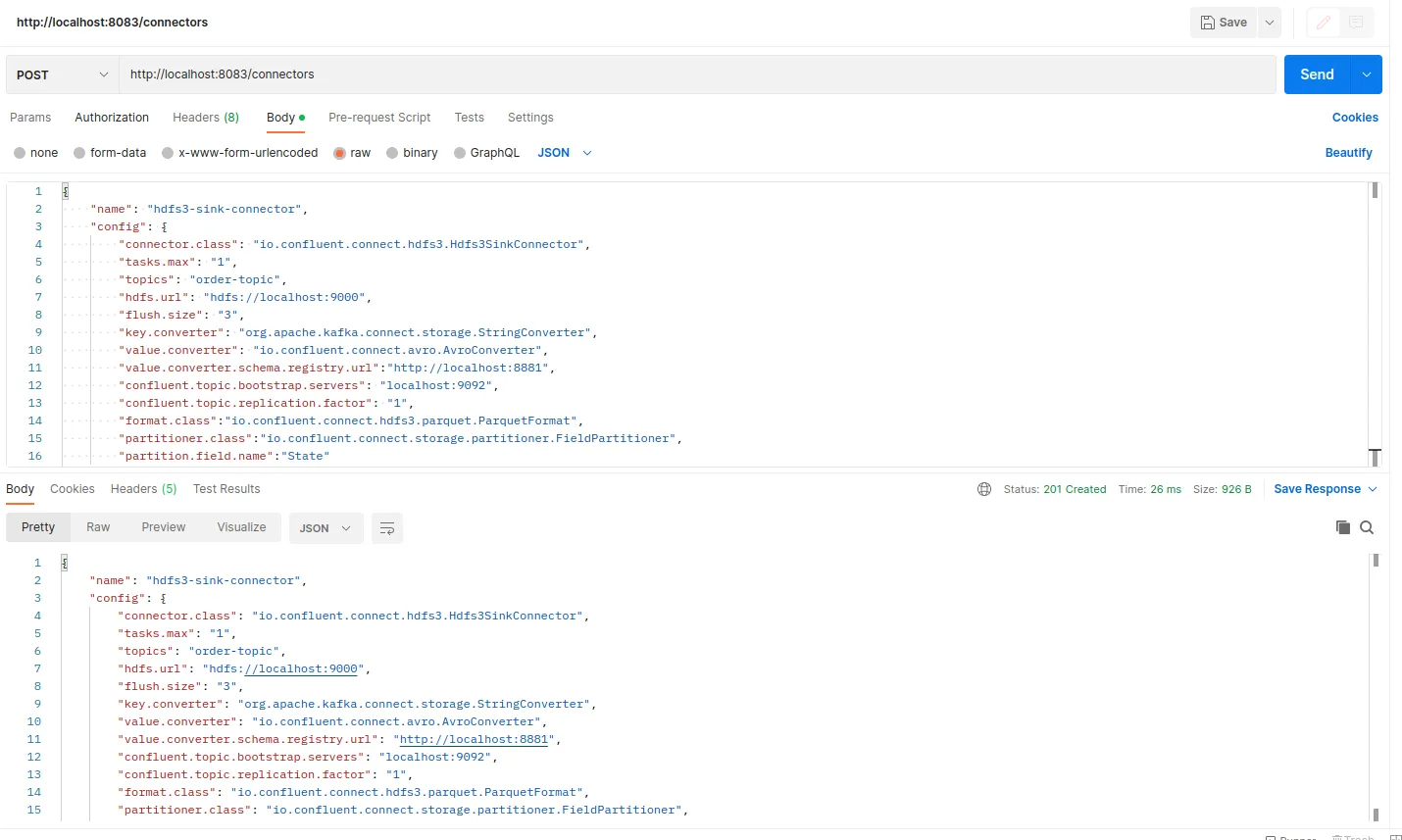
{
"name": "hdfs3-sink-connector",
"config": {
"connector.class": "io.confluent.connect.hdfs3.Hdfs3SinkConnector",
"tasks.max": "1",
"topics": "order-topic",
"hdfs.url": "hdfs://localhost:9000",
"flush.size": "3",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter": "io.confluent.connect.avro.AvroConverter",
"value.converter.schema.registry.url":"http://localhost:8881",
"confluent.topic.bootstrap.servers": "localhost:9092",
"confluent.topic.replication.factor": "1",
"format.class":"io.confluent.connect.hdfs3.parquet.ParquetFormat",
"partitioner.class":"io.confluent.connect.storage.partitioner.FieldPartitioner",
"partition.field.name":"State"
}
}
Konfigürasyonumuz yukarıdaki gibidir. İlgili connector’u çalıştırmak için ben Postman aracını kullandım siz CLI yardımıyla da bunu yapabilirsiniz.
AKHQ Web UI ekranına giderek başarılı şekilde çalışıp çalışmama durumunu takip edebiliriz.
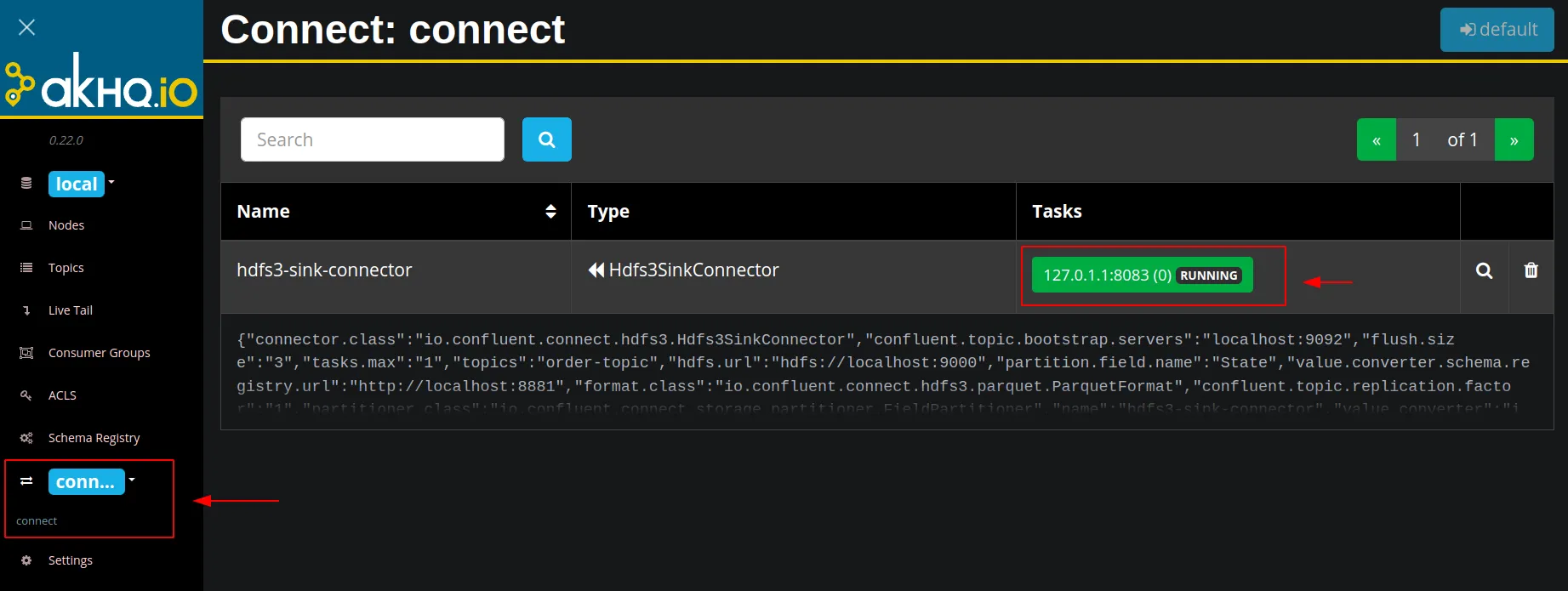
Sağlıklı bir şekilde çalıştığını gördük. Şimdi son olarak HDFS tarafındaki kontrolümüzü yaparak senaryomuzu tamamlamış olacağız.
hdfs dfs -ls /topics/order-topic/
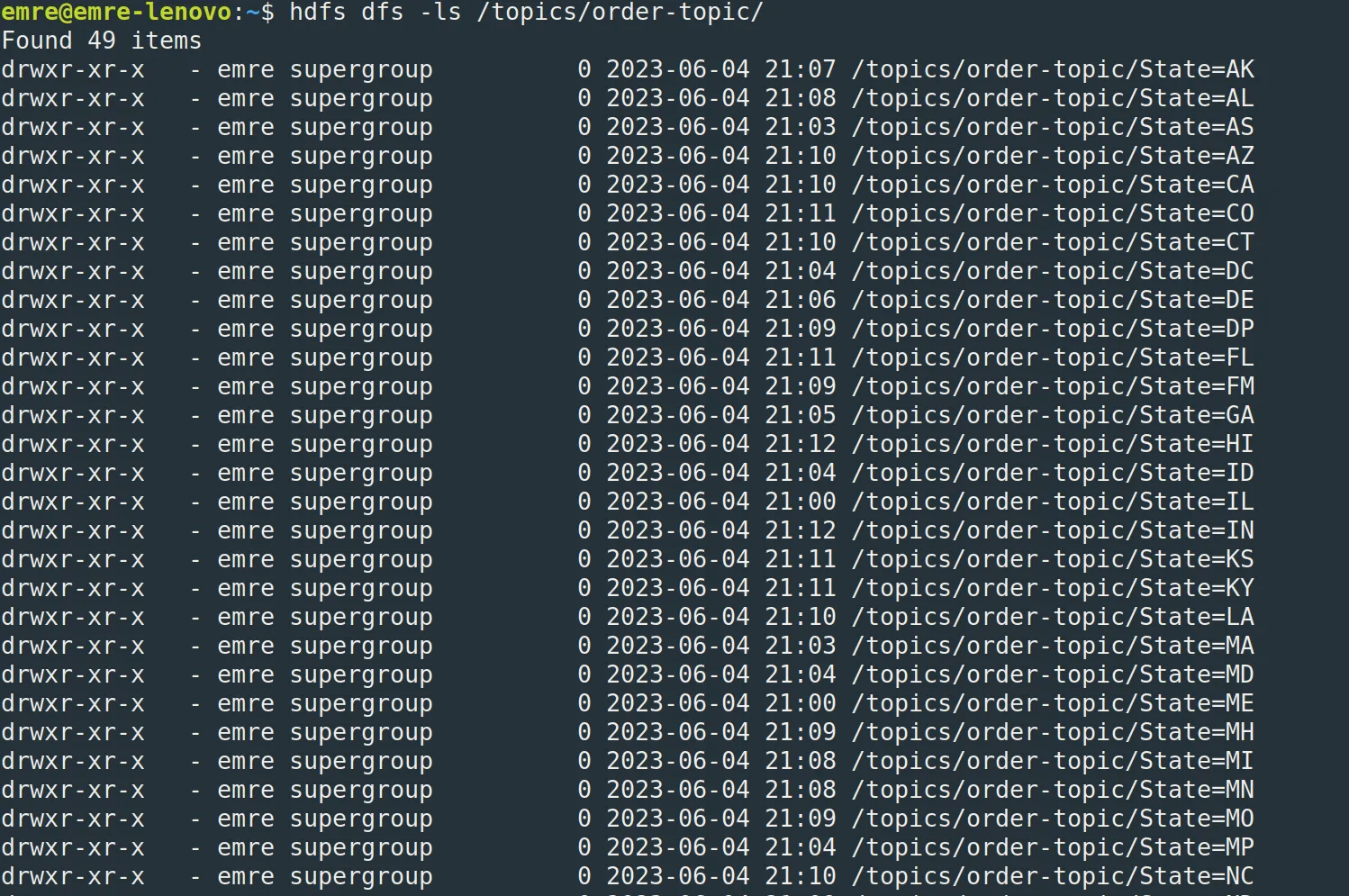

HDFS tarafına baktığımızda istediğimiz gibi State kolonunu dikkate alarak verileri ayırmış ve parquet formatında kaydetmiş.
Umarım faydalı bir yazı olmuştur. Sorularınız ve önerileriniz için benimle iletişime geçebilirsiniz. Teşekkürler.