Streaming with Continuous Airflow

Streaming with Continuous Airflow
Real-time data pipelines are increasingly crucial in today’s data-driven systems. Traditional batch processing (e.g., nightly Spark jobs) introduces latency that doesn’t suit use cases like live monitoring, fraud detection, or personalized content. Apache Airflow has long been a go-to orchestrator for batch workflows, but how can we leverage it for streaming or near real-time pipelines? In this article, we explore Airflow’s new continuous scheduling capability and how to build a streaming data pipeline using Apache Kafka, PySpark Structured Streaming, and Apache Phoenix — all orchestrated and monitored through Airflow’s UI instead of ad-hoc scripts. This approach provides a clear, maintainable workflow for streaming tasks, offering visibility and management through Airflow’s interface.
Airflow for Streaming Pipelines?
Apache Airflow is an open-source platform to programmatically author, schedule, and monitor workflows. It was originally designed for finite, batch-oriented tasks (think daily ETL jobs) and is not a stream processing engine itself. In fact, Airflow’s documentation warns that it’s not intended for ultra low-latency or continuous event processing in the same way specialized streaming frameworks are. However, with the right configuration, Airflow can orchestrate micro-batch streaming jobs and integrate with streaming systems. In other words, Airflow can coordinate real-time workflows by working alongside tools like Apache Kafka and Spark Structured Streaming.
Recent versions of Airflow (2.4+ and the upcoming 3.x) introduce features that make streaming workflows easier to manage. One such feature is the Continuous Timetable (schedule @continuous), which lets a DAG run in a loop, starting a new run immediately after the previous one finishes. This effectively enables a continuous pipeline within Airflow, while still keeping max_active_runs=1 to ensure only one instance runs at a time. Using continuous scheduling, you no longer need to rely on external cron jobs or while-loop scripts to repeatedly trigger your streaming job – Airflow’s scheduler handles it, and you get full visibility in the Airflow UI.
It’s important to set expectations: Airflow with continuous scheduling is best for near real-time or micro-batching scenarios (e.g. jobs running every minute or few minutes). It’s not suitable for millisecond-level latency or truly unending streaming without micro-batches. For sub-minute processing requirements, you’d still use specialized streaming frameworks and message queues (Kafka, Flink, etc.) in the pipeline— in fact, Kafka itself will be a central component in our example. Airflow’s role is to orchestrate and monitor the pipeline steps, not to replace the streaming engines.
Use Case and Architecture Overview
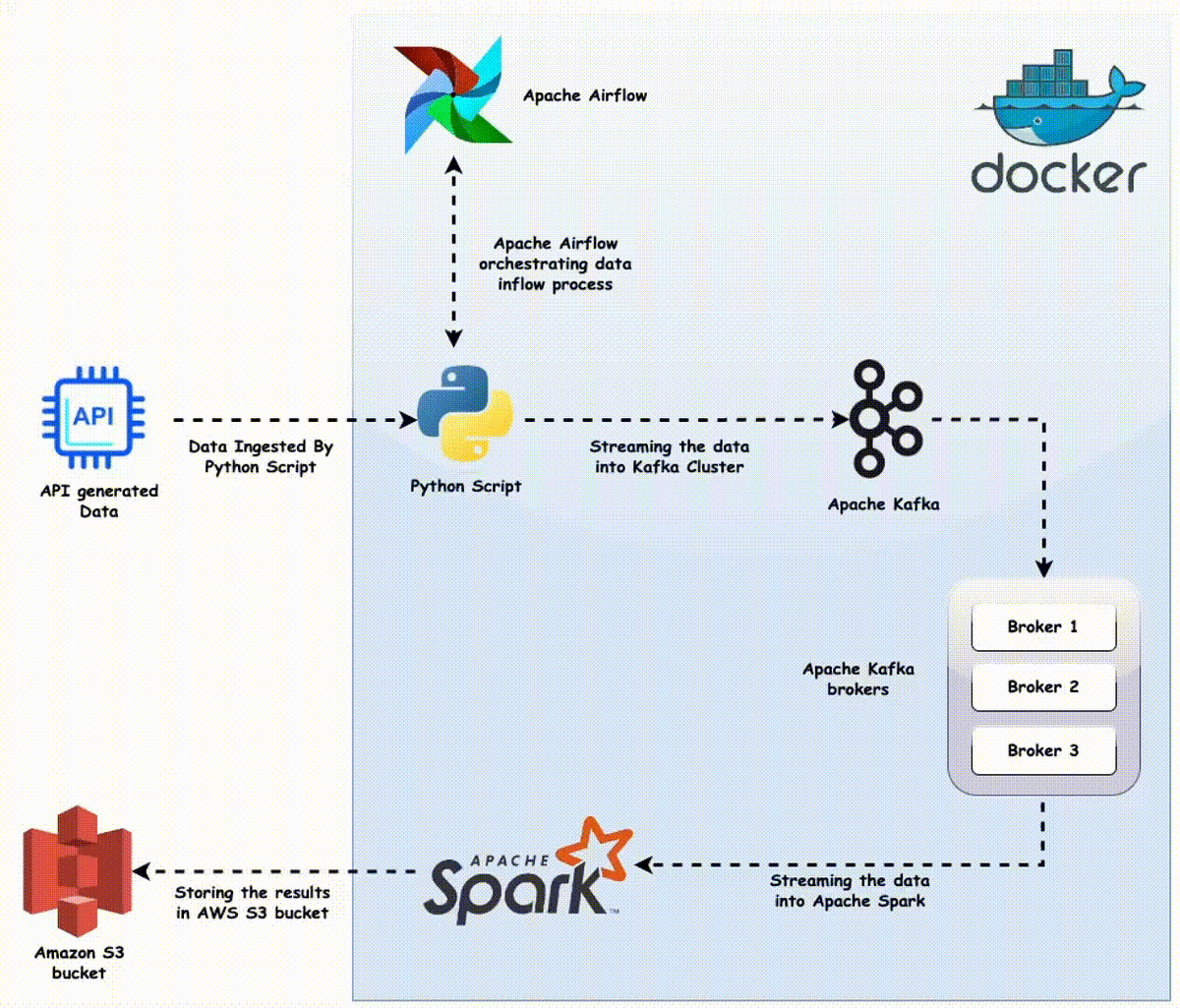
Let’s consider a practical scenario: a telecom company wants to process network event streams (call records, data usage events, etc.) in near real-time for analytics and alerting. The data engineering team needs to aggregate these streaming events continuously and make the results available quickly for other systems (like dashboards or billing checks). Traditionally, one might create a long-running Spark Streaming job and manage it via scripts or supervise it manually in a terminal. Instead, we will build a more robust solution using Airflow’s DAG to coordinate the streaming pipeline.
Technologies in our Pipeline:
- Apache Kafka — a distributed event streaming platform used to ingest and buffer the incoming events. Kafka will serve as the source of raw event data (and also as a sink for processed results, in this design). It’s a high-throughput, fault-tolerant message broker that decouples producers and consumers of data.
- Apache Spark Structured Streaming — Spark’s scalable stream processing engine for real-time data processing. We use PySpark to define a streaming computation that reads from Kafka, performs aggregations, and writes results out.
- Apache Phoenix — a SQL layer on top of HBase (NoSQL database) used here for fast storage and querying of aggregated results. Phoenix allows us to treat HBase as a relational datastore and supports low-latency upserts and queries via SQL. In our pipeline, Phoenix will store the telco aggregates (making them queryable in real-time by other applications).
- Apache Airflow — the orchestrator that ties everything together. Airflow will schedule the Spark streaming job to run continuously, manage its execution, and provide monitoring via the Airflow UI (so we don’t need custom shell scripts for scheduling or monitoring).
Pipeline Flow: We will implement a continuous loop that processes data in small batches. Here’s an outline of the pipeline steps:
- Ingest Events from Kafka: Airflow triggers a Spark Structured Streaming job that reads new events from a Kafka topic (for example, a topic receiving live call detail records or data usage events).
- Aggregate Using Spark (with Phoenix): The Spark job groups and aggregates the streaming data — for instance, computing total call minutes or data usage per user over a time window. Phoenix comes into play if we need to combine streaming data with existing records or update cumulative totals. Spark can use Phoenix to update and fetch reference data (e.g. current totals) during these aggregations.
- Store Aggregated Metrics to Phoenix: The computed aggregates (e.g. per-user or per-cell-tower metrics) are written into Phoenix tables in HBase. Phoenix’s ability to upsert data means each batch’s results can update the latest state, making the data available for immediate SQL queries (e.g., an API or dashboard can query “today’s usage per user” from Phoenix).
- Publish Results to Kafka: Optionally, the pipeline also produces the processed results to another Kafka topic. This can be useful for downstream systems that prefer to consume the aggregates as a stream (for example, an alerting service or a real-time dashboard application listening on a Kafka topic of “aggregated usage events”).
By orchestrating these steps in Airflow, we gain benefits like error handling, retrial logic, scheduling controls, and observability through Airflow’s web UI. The UI will show a DAG graph of the tasks, logs from each Spark job execution, and the status of each run, all in one place — as opposed to combing through server logs or custom monitors when using shell scripts.
Before diving into code, it’s worth visualizing the architecture:
- Source: Kafka topic (raw telco events)
- Processing: Spark Structured Streaming job (running in micro-batch mode under Airflow’s control)
- Storage: Phoenix/HBase for aggregates (OLTP-style analytics store)
- Sink: Kafka topic (processed/aggregated events for further use)
- Orchestration & Monitoring: Airflow (DAG with continuous schedule, Airflow UI for monitoring)
(If you have a working Airflow environment with Kafka, Spark, and Phoenix available, you can implement this architecture. For simplicity, we assume these services are already configured and running, and that Airflow’s workers can access Spark and Kafka.)
Airflow DAG — Continuous Scheduling Setup
First, let’s configure the Airflow DAG to run continuously. We’ll use Airflow’s @continuous schedule to ensure the DAG keeps triggering new runs back-to-back. It’s important to set max_active_runs=1 so that only one instance of the DAG runs at a time (avoiding overlap). We’ll also disable catchup since we only care about the current stream of data, not historical scheduling. Below is a snippet of how the DAG definition might look:
from datetime import datetime
from airflow.decorators import dag
from airflow.operators.bash import BashOperator
@dag(
start_date=datetime(2023, 1, 1),
schedule="@continuous", # run continuously, one execution after another
max_active_runs=1, # only one run at a time
catchup=False, # do not backfill old runs
tags=["streaming", "spark", "kafka"]
)
def telco_streaming_pipeline():
# Task: Submit Spark streaming job
spark_stream_task = BashOperator(
task_id="spark_telco_agg",
bash_command=(
"spark-submit --master yarn "
"--deploy-mode cluster "
"/path/to/telco_streaming.py"
)
)
# In a real setup, you might use SparkSubmitOperator or a custom operator.
# Here we use BashOperator for simplicity to call spark-submit.
# (Additional tasks could be added here, e.g., a sensor to verify job health or a notification task)
# Define dependencies (if multiple tasks exist)
# For a single task DAG, no dependencies are needed.
# If there were downstream tasks, you'd set spark_stream_task >> next_task.
dag = telco_streaming_pipeline()
In this DAG:
- We used the
@dagdecorator to declare a DAG starting at a certain date (in practice, start_date can be any past date since continuous DAGs will just run now onwards). schedule="@continuous"enables the continuous timetable. This means as soon as one DAG run finishes (success or failure), the scheduler will kick off the next run almost immediately. Unlike a cron schedule, there’s no fixed interval; it’s a looper.- We set
max_active_runs=1to ensure only one instance runs at a given time (this prevents overlapping runs which could happen if a run takes longer than the schedule interval, though with continuous it’s essentially required to be 1). - The single task in the DAG is
spark_telco_agg, which uses a BashOperator to call a Spark submit command. This command runs our PySpark structured streaming job (the scripttelco_streaming.py). We assume a YARN cluster deployment (--master yarn --deploy-mode cluster) for Spark – in cluster mode, the driver lives on the cluster, and importantly the spark-submit command will exit once the job is successfully submitted, not waiting for the job to finish. This detail ensures the Airflow task doesn’t stay running forever. The Spark streaming job will then run on the cluster continuously, processing data, while Airflow considers the task done after submission. If the streaming job stops or fails on the cluster, we can have Airflow detect that in the next run (or via a sensor task) and possibly restart it.
Why not run Spark streaming as a normal task that never ends? Airflow tasks are expected to finish eventually. Running a never-ending streaming job in a task would mean the task never completes, which isn’t suitable — the scheduler wouldn’t know to trigger new runs, and monitoring a hanging task is problematic. That’s why we deploy the Spark job in cluster mode with a non-blocking submit (using spark.yarn.submit.waitAppCompletion=false under the hood, as one would configure for long-running YARN applications). This way, Airflow triggers the streaming job and can move on, allowing the continuous DAG to schedule the next cycle (for example, to perform a periodic health check, or simply to keep the loop going so that if the job terminates, a new one can be launched).
In summary, the Airflow DAG continually ensures a Spark streaming job is running. The Airflow UI will show successive DAG runs (e.g., streaming_pipeline_run 2023-01-01T00:00:00+00:00, then ...00:01:00+00:00, etc., or some logical timestamp for each run) executing one after another. You can watch the task logs in the UI to see the spark-submit output (which could include Spark’s streaming logs or any custom metrics you log). If a run fails (say the spark-submit itself fails to launch the job), Airflow will report it and, depending on your DAG settings, could retry it. The continuous schedule means even on failure, a new run will start immediately after, which is useful to attempt restarting the streaming job. (You could also add Airflow logic to handle alerts or to only restart after certain conditions – for brevity we won’t delve into those here.)
Spark Structured Streaming Job — Reading from Kafka and Writing to Phoenix
Now let’s look at the Spark job code (telco_streaming.py) that does the actual data processing. This PySpark Structured Streaming application will be submitted by Airflow in each DAG run (or kept running on the cluster). Its goal: read events from a Kafka topic, aggregate them, interact with Phoenix, and output results.
Assumptions: The Kafka cluster address, topic names, and Phoenix connection details (like Zookeeper quorum for Phoenix) are known and accessible from the Spark cluster. Also, the Phoenix Spark connector (or JDBC driver) is available on the classpath for Spark to use.
Below is a simplified example of what the Spark streaming code could look like:
from pyspark.sql import SparkSession
from pyspark.sql.functions import from_json, col, sum as spark_sum
# Initialize SparkSession (ensure Kafka & Phoenix connectors are included via packages/jars)
spark = SparkSession.builder \
.appName("TelcoStreamingAggregation") \
.getOrCreate()
# Subscribe to the Kafka topic for raw events
raw_events_df = spark.readStream.format("kafka") \
.option("kafka.bootstrap.servers", "broker:9092") \
.option("subscribe", "telco-events") \
.option("startingOffsets", "latest") \ # start from latest for new runs
.load()
# Assuming events are JSON messages, define schema or use from_json to extract fields
# For example, an event might have {"userId": "...", "callDuration": 30, "towerId": "...", ...}
# Here we'll parse the Kafka value as JSON into columns
from pyspark.sql.types import StructType, StringType, LongType
event_schema = StructType() \
.add("userId", StringType()) \
.add("callDuration", LongType()) \
.add("towerId", StringType()) \
.add("timestamp", StringType()) # or TimestampType if proper format
events_df = raw_events_df.selectExpr("CAST(value AS STRING) as json_str") \
.select(from_json(col("json_str"), event_schema).alias("event")) \
.select("event.*") # flatten the struct to columns
# Aggregate streaming data: e.g., total callDuration per user (this could also be windowed by time)
agg_df = events_df.groupBy("userId").agg(spark_sum("callDuration").alias("total_call_duration"))
# Upsert the aggregate results to a Phoenix table and also produce to Kafka.
# We'll use foreachBatch to perform batch writes on each micro-batch.
def process_batch(batch_df, batch_id):
# Write batch results to Phoenix (HBase) table
batch_df.write.format("phoenix") \
.mode("overwrite") \
.option("table", "TELCO_USAGE") \
.option("zkUrl", "phoenix-zookeeper:2181") \
.save()
# For Phoenix, using mode "overwrite" or "upsert" depends on connector; assume upsert behavior.
# This will write/overwrite aggregated data by userId in the TELCO_USAGE table.
# Also send the aggregated results to an output Kafka topic as JSON
batch_df.selectExpr("to_json(struct(*)) AS value") \
.write.format("kafka") \
.option("kafka.bootstrap.servers", "broker:9092") \
.option("topic", "telco-agg-events") \
.save()
# Start the streaming query with foreachBatch for custom sink logic
query = agg_df.writeStream \
.outputMode("update") \ # using update mode since we're aggregating
.foreachBatch(process_batch) \ # use foreachBatch to handle each micro-batch
.option("checkpointLocation", "hdfs:///user/airflow/checkpoints/telco_stream") \
.start()
query.awaitTermination()
A few notes on this code:
- We read from Kafka using Spark’s built-in Kafka source. The
raw_events_dfwill continuously stream data from the Kafka topic"telco-events". We setstartingOffsets="latest"so that each new Spark job starts at the end of the topic (we won’t reprocess old events in this example). In a real scenario with continuous running and checkpointing, the offsets would be stored in the checkpoint and you’d typically use"earliest"or specific offsets with proper checkpoint management. Here we assume a steady continuous run. - We parse the Kafka message values from bytes to a JSON string, then extract fields using a schema. This gives us a DataFrame
events_dfwith columns likeuserId,callDuration, etc., representing the incoming stream of events. - We perform an aggregation: summing the call durations per user (grouping by
userId). Thisagg_dfwill update whenever new call events for a user arrive. TheoutputMode("update")means each micro-batch will output the latest value for each group that changed in that batch (so we can upsert the new totals). - The critical part is using
foreachBatchinwriteStream. This allows us to custom-handle each micro-batch of results in code. In theprocess_batchfunction, we take the batch DataFrame and: - Write it to a Phoenix table
TELCO_USAGE. We use the Phoenix connector (which must be available – e.g., by using thesparkphoenixpackage or appropriate jar). Themode("overwrite")here is conceptually doing an upsert (Phoenix will merge by primary key). Phoenix provides a JDBC driver that the connector uses to talk to HBase. After this, the Phoenix table will have the latest total call duration per user (keyed by userId). - Then we take the same batch and send it to another Kafka topic
"telco-agg-events"by converting each row to a JSON string (theto_json(struct(*))trick flattens the row to a single JSON string in a column namedvalue, which the Kafka sink expects). This produces a message per user update, which could be consumed by other systems (for example, to trigger alerts if a user’s usage exceeds a threshold). - We specify a
checkpointLocationin HDFS (or any durable storage) to store offsets and state between batches. This is important for exactly-once or at-least-once guarantees in Spark Structured Streaming. - Finally, we start the query and call
awaitTermination()to keep the driver alive. In cluster mode, this Spark application will keep running, processing new events continuously until stopped.
This Spark job effectively runs continuously, but thanks to how we triggered it via Airflow, we have control over it from the Airflow side. We could, for instance, stop the job by canceling the YARN application or by not scheduling a new one if not needed. Each Airflow DAG run ensures that if the previous job finished or failed, a new one will start. If the job keeps running, our DAG might simply kick off, check that a job is already running, and do nothing or monitor it (depending on implementation).
Phoenix integration: Note that using Phoenix in a streaming job might involve some nuances (like making sure the Spark->Phoenix writes are idempotent or using the Phoenix Spark plugin for better performance). The code above assumes a straightforward use of Phoenix’s Spark connector for demonstration. Phoenix allows low-latency upserts and SQL queries on the HBase data, which suits our need to have the aggregated data quickly accessible. In practice, one might also use Phoenix to join static reference data to the stream (e.g., enriching events with user info from a Phoenix table) — those would be additional steps in the transformation.
Monitoring the Streaming Pipeline in Airflow UI
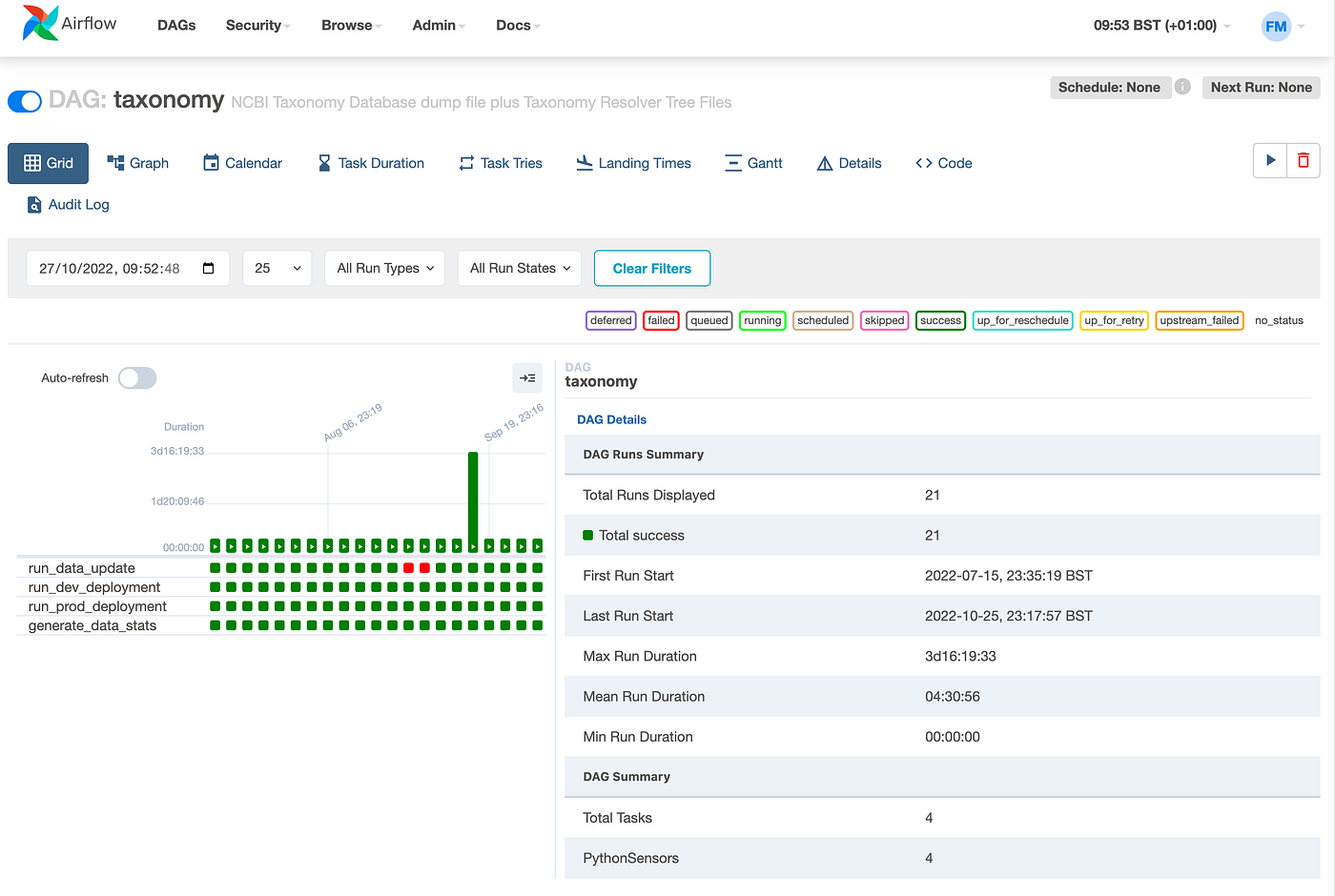
One of the biggest advantages of using Airflow for this pipeline is the operational visibility and control you gain:
- DAG Monitoring: In the Airflow web UI, you will see the DAG
telco_streaming_pipelinerunning continuously. The DAG run list will show a series of runs (with logical dates/timestamps). Since we used@continuous, Airflow doesn’t wait for a specific interval – as soon as one run is done, the next is queued. This means the “next run” might start seconds after the previous one. The UI will reflect runs perhaps labeled with the same execution date (since logically it might treat it as one ongoing run with manual triggers), or with incremental identifiers (Airflow 2.4+ changed how continuous runs are labeled). In any case, you’ll observe that as long as the Spark task completes (or even if it fails), Airflow will spawn a new run. - Task Logs: Clicking on the task
spark_telco_aggin the UI allows you to see the logs from the bash command. Here you would find the output of thespark-submitcommand. If the Spark job launched successfully, you might just see logs about submitting to YARN. If there was an error (like the script had an issue), it would appear here. This is much more convenient than tailing logs on a server manually. - State and Retries: If the Spark submit fails (perhaps Kafka brokers were unreachable or a code bug causes immediate failure), Airflow can be configured to retry the task automatically a certain number of times. The UI will show the task in a failed state and then transitioning to retry. Alerts (email or other) can be set up through Airflow’s alerting mechanisms to notify the team of failures. All of this reduces the need for custom monitoring scripts.
- Stopping/Pausing: If you need to stop the pipeline (for example, for maintenance on Kafka or deploying a new version of the Spark job), you can turn off the DAG in the UI or mark it as inactive. This will stop scheduling new runs. You might also manually stop the Spark streaming job via YARN or a cancel command if it’s still running. Once you’re ready to resume, simply turn the DAG back on. This control is much cleaner than killing Linux processes or editing cron schedules.
- Integration with Other Pipelines: Airflow can also trigger downstream processes after or during the streaming pipeline. For instance, you could have another DAG (or task) that periodically queries the Phoenix table and generates a report, or a DAG that is triggered by the completion of each micro-batch (though with continuous scheduling, we usually don’t trigger off each run externally — instead we might use event-based mechanisms like Airflow Datasets if needed). The key is that Airflow provides a central hub to manage various pipeline components in one view.
In contrast, if one were “scheduling and monitoring via shell or scripts”, as many beginners might do, you’d probably have a cron entry or a long-lived shell script to run the Spark job, and separate logic to check if it’s running or restart it on failure. This approach is brittle and lacks observability – if the job dies at 3 AM, you might not know until it’s too late. With Airflow, you get built-in scheduling, dependency management, and alerting in a single platform.
Conclusion and Best Practices
Using Apache Airflow’s continuous scheduling feature, we built a streaming data pipeline that reads from Kafka, processes data with Spark Structured Streaming, and updates a Phoenix (HBase) datastore while also emitting results to Kafka. This setup is powerful for implementing near real-time pipelines with clear orchestration and monitoring. Developers new to Airflow or streaming can benefit from this approach by having a familiar Airflow DAG paradigm to control streaming workflows, rather than dealing with unmanaged scripts or complex custom schedulers.
A few best practices and takeaways for those looking to try this in practice:
- Ensure One Job at a Time: The combination of
schedule="@continuous"andmax_active_runs=1is key. This prevents overlaps and keeps resource usage in check. Airflow will queue the next run only when the prior one finishes. - Leverage Checkpointing: When orchestrating streaming jobs via Airflow, design the jobs to be restart-friendly. In our Spark job, using a checkpoint directory means if the job restarts, it can pick up where it left off (e.g., it won’t re-read all past Kafka messages, only new ones). This idempotency is crucial because Airflow may restart the job on failures.
- Use Deferrable Operators/Sensors if needed: Airflow 2.x introduced deferrable operators and sensors that are efficient for waiting on events. If your pipeline requires waiting for an external trigger (say, waiting for a Kafka message or a file arrival), you can use a sensor in a continuous DAG. Continuous DAGs are especially useful combined with sensors for irregular events — the DAG will keep running and waiting without a schedule gap. Just be mindful of timeouts and avoid indefinite hangs.
- Monitoring and Alerts: Set Airflow alerts on task failure. It’s easier to manage streaming jobs when you get notified the moment something stops. You can also push custom metrics (like how many records were processed in the last batch) to logs, which Airflow can aggregate or forward to monitoring systems.
- When to consider alternatives: If your use case truly demands real-time (sub-second) latency or extremely high frequency triggers, Airflow might not be the ideal orchestrator in isolation. Technologies like Apache Flink or Kafka Streams that are built for continuous processing could be more appropriate. That said, Airflow can still play a role upstream or downstream (for example, scheduling nightly model retraining that complements real-time inference pipelines, or handling batch fallback processing). Always match the tool to the requirements.
By integrating Airflow with streaming systems, we get the best of both worlds: the reliability and clarity of Airflow’s orchestration, and the power of Kafka and Spark for handling streaming data. The Airflow UI becomes your control center for streaming pipelines — no more black-box shell scripts running in the background. This makes the solution more maintainable and accessible, especially for teams where some members are already comfortable with Airflow from batch workflows.
In summary, Airflow’s continuous DAGs enable a continuous airflow of data — orchestrating streaming tasks in a manageable fashion. With the example above, a junior developer or anyone new to Airflow can follow a template to implement their own streaming pipeline. It demystifies streaming by showing that with a bit of setup, you can monitor and manage it just like any other Airflow job. So, next time you are tempted to run a long-lived streaming script by hand, consider giving Continuous Airflow a try for a more elegant solution to streaming data pipelines.
References
- Apache Airflow Scheduling & Continuous Timetable
https://airflow.apache.org/docs/apache-airflow/stable/concepts/scheduling.html
(See the “Continuous Timetable” section for@continuousscheduling andmax_active_runsguidance.) - Spark Structured Streaming + Kafka Integration Guide
https://spark.apache.org/docs/latest/structured-streaming-kafka-integration.html - Apache Phoenix Documentation
https://phoenix.apache.org/
(Includes details on using Phoenix as an SQL layer over HBase and integrating with Spark.) - Airflow’s Best Practices for Sensors & Deferrable Operators
https://airflow.apache.org/docs/apache-airflow/stable/concepts/sensors.html
(Covers deferrable sensors and how they keep slots free while waiting.) - Apache Kafka® Documentation
https://kafka.apache.org/documentation/
(General Kafka concepts, producers/consumers, and topics.)
Citations
- Astronomer.io — Deep Dive on Airflow Continuous DAGs
https://www.astronomer.io/blog/continuous-dags-in-airflow - Reddit — Discussion on Using Airflow for Near‑Real‑Time Scheduling
https://www.reddit.com/r/dataengineering/comments/abcd12/using_airflow_for_streaming_and_near_real_time/ - CloudThat.com — Tutorial: Spark Structured Streaming with Kafka
https://cloudthat.com/blog/spark-structured-streaming-kafka-integration/ - GitHub — Apache Phoenix Spark Connector Repository
https://github.com/apache/phoenix/blob/master/phoenix-spark/src/main/scala/org/apache/phoenix/spark/